
在过去的2022卡塔尔世界杯中,我们可以看到其用到了各种先进的技术,其中有一项是比较吸引我的,那就是半自动越位技术。这项技术的其中的一个分支就是我今天要说的内容。如下图所示。球员身上的关键点检测技术就是今天要说的内容。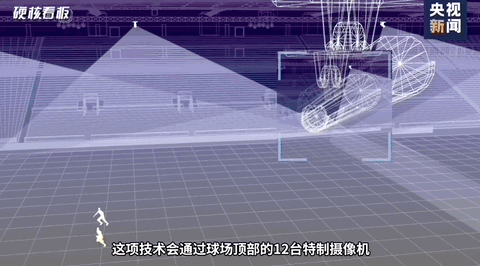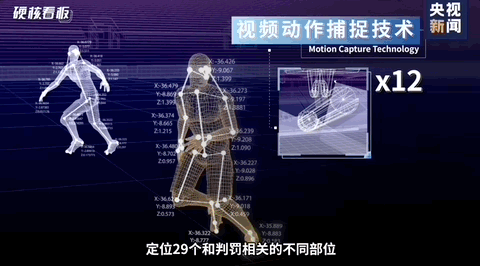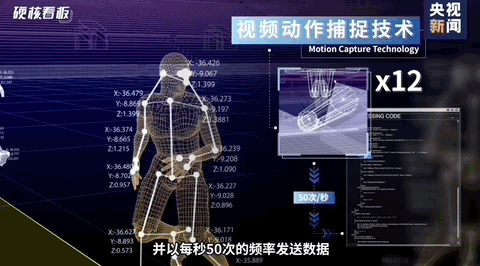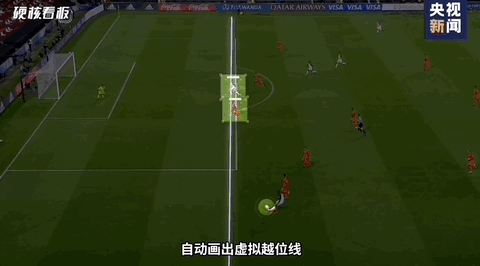
二、关键点检测的分类及应用
除了我们看到足球比赛中所用的半自动越位识别技术(SAOT),还有其他的关键点检测技术,大致可以划分为三类:pose、face、hand。
下面是在Google提供的开源工具箱MediaPie[2]中找到的相关资料,大家有兴趣可以自行去查看相关内容。
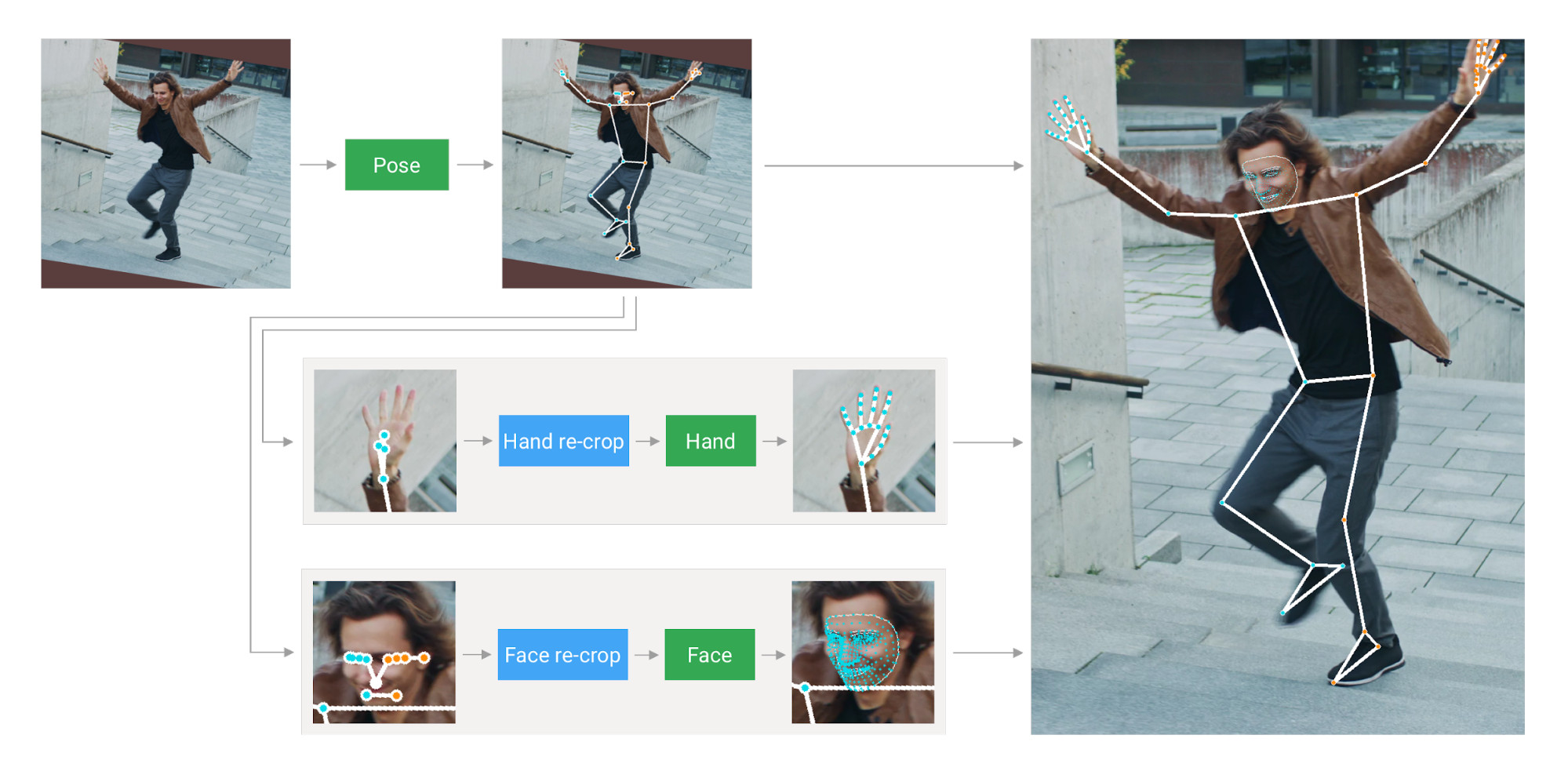
从这里我们不难看出,球员身上的检测是基于Pose,也就是姿态的检测。那基于Pose 的关键点检测还有哪些应用?
笔者给出以下应用场景:运动指导、深度学习摔倒检查、基于深度学习的犯罪嫌疑人行为预测等方面。
基于脸部的关键点检测应用场景主要有:表情识别、情绪分析、脸部定位等。
由于今天主要讲解手部关键点检测所以对姿态和脸部的关键点检测介绍就到这里,感兴趣的话可以去查询相关资料文献。
这里给大家展示手部关键点检测在华为Mate40手机中的应用。
三、手部关键点检测原理

这里的展示的手部关键点检测时基于Google的开源项目进行讲解,用到的方法是检测手部21个关键点,从而确定手部轮廓,达到手部关键点检测的目的。

如上图所示手部关键点检测可以分为两步,第一步就是定位到手部的位置,这一部分相对较简单,使用主流的深度学习框架,通过有监督学习是很容易训练出一个精确度还不错的模型。第二步就是对第一步提取到的手部区域进行21个关键点检测,若此部分按照之前的方法进行有监督学习训练出一个模型来检测,效果是非常差的,为什么呢?因为摄像头所得到的信息是二维的,而我们手掌是三维的,且手几乎是人体最灵活的部位之一,倘若只通过简单的有监督学习进行检测是无法达到想要的效果,好在我们的脚下有巨人,早在2020年Google在计算机视觉顶会提出过一个模型GHUM[3]这里做了相关的一些工作,大概意思就是谷歌通过拍摄人体三维信息来构建一个模型,让模型能适应二维图像。
下面分别是第一步和第二步模型的一些相关参数。
PDM模型相关参数:
DETECTOR MODEL SPECIFICATIONS
Model Type
● Convolutional Neural Network
Model Architecture
● Single-shot detector model
Inputs
● A frame of video or an image, represented as a
192 x 192 x 3 tensor. Channels order: RGB with
values in [0.0, 1.0].
Output(s)
● A float tensor 2016 x 18 of predicted
embeddings representing anchors
transformation which are further used in Non
Maximum Suppression algorithm.
HLM模型相关参数:
TRACKER MODEL SPECIFICATIONS
Model Type
● Convolutional Neural Network
Model Architecture
● Regression model
Inputs
● A crop of a frame of video or an image,
represented as a 224 x 224 x 3 tensor. Channels
order: RGB with values in [0.0, 1.0].
Output(s)
● A float scalar represents the presence of a hand
in the given input image.
● 21 3-dimensional screen landmarks represented
as a 1 x 63 tensor and normalized by image size.
This output should only be considered valid
when the presence score is higher than a
threshold.
● A float scalar represents the handedness of the
predicted hand. This output should only be
considered valid when the presence score is
higher than a threshold.
● 21 3-dimensional metric scale world landmarks
represented as a 1 x 63 tensor. Predictions are
based on the GHUM hand model. This output
should only be considered valid when the
presence score is higher than a threshold.
PDM +HLM 就可以实现从原图的输入到下图手掌关键点检测的效果。下一步,下一步就可以开始虚拟计算器设计了。

四、基于关键点检测的手势虚拟计算器
这里给出手部关键点检测的设计流程,其中第一步是检测手部信息,包括手部定位和手部关键点检测,这两步完成后就可以进行虚拟计算器界面的设计,这里用的是python进行设计,相对较简单,源码也贴在下面,感兴趣的小伙伴可以去动手尝试一下。最后一步也是最关键的一步就是将手部的运动状态和计算器的操作逻辑进行绑定,从而实现手势操控计算器的目的。

python源码展示[4]
1 | import cv2 |
五、Demo展示
最后一部分就是一个小Demo。
参考文献
- 本文标题:手势操控虚拟计算器
- 创建时间:2023-04-01 09:26:11
- 本文链接:2023/04/01/mediapipehand/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!